Reflexion: 「自己反省」で賢くなるAIエージェントの仕組み【論文解説】
GPT-4のコーディング性能を80%から91%に向上させた「Reflexion」フレームワーク。重み更新なしで、言葉によるフィードバックを通じて学習する「言語的強化学習」の画期的な手法を解説します。
「AIが失敗から学んでくれたらいいのに」
そう思ったことはありませんか? 従来の大規模言語モデル(LLM)は、一度学習したらパラメータは固定され、試行錯誤から動的に学ぶことは苦手でした。失敗しても、次のトライで同じ間違いを繰り返すことがよくあります。
この記事では、そんな常識を覆す論文 「Reflexion: Language Agents with Verbal Reinforcement Learning」 を解説します。この手法を使えば、AIエージェントは自らの行動を「言葉」で反省し、重み更新なしで驚異的なパフォーマンス向上を実現できます。
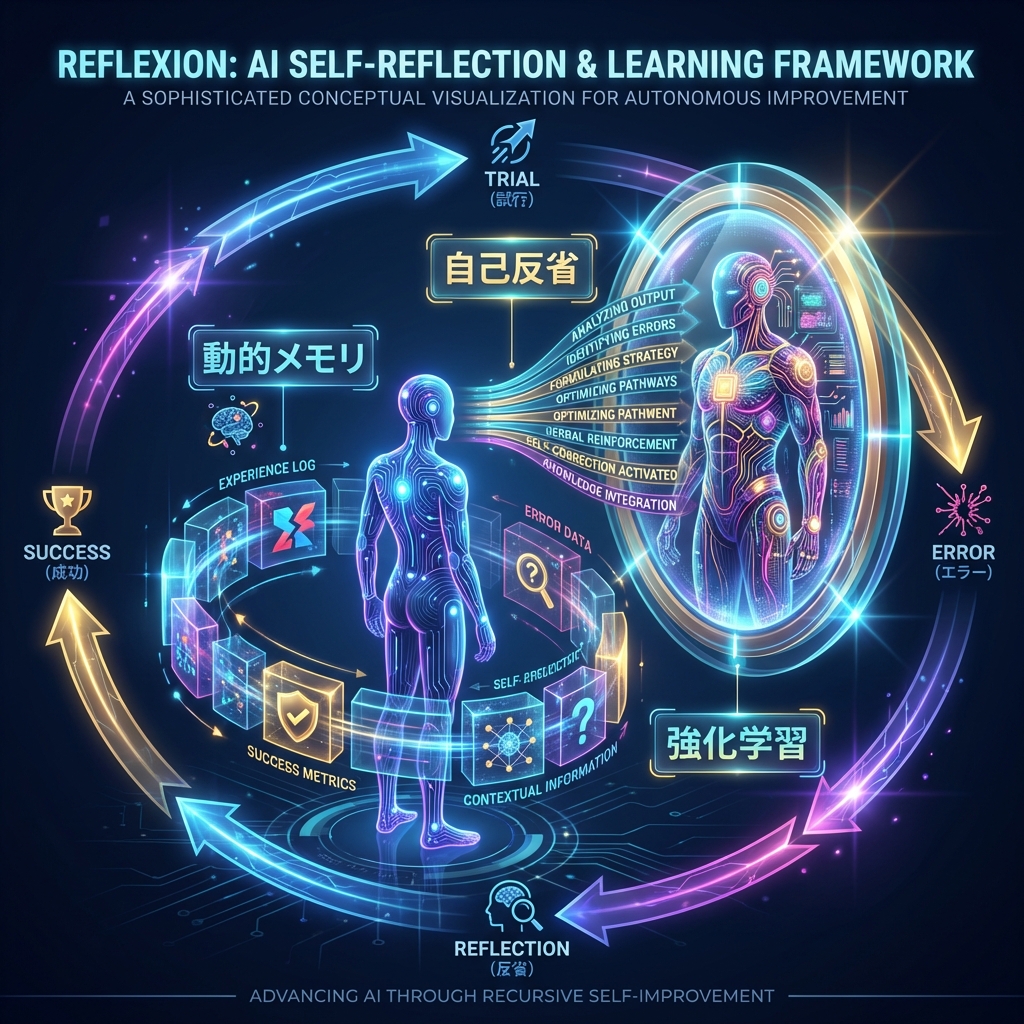
1. Reflexionとは?:「言語」による強化学習
一言で言えば、Reflexionは 「AIエージェントに『反省文』を書かせることで、次の行動を改善させるフレームワーク」 です。
通常の強化学習が数値(報酬)を使ってモデルの重み(Weight)を更新するのに対し、Reflexionは 「言葉(Verbal Feedback)」 を使ってエージェントの短期記憶を更新します。
仕組みのメタファー
新人エンジニアの教育を想像してください。
- 従来の手法: バグを出したら、無言でスコアを下げる(AIは何が悪いか気づきにくい)。
- Reflexion: 「変数の型が間違っていたね。次は確認しよう」と言葉でアドバイスし、本人に「次は型を確認する」とメモさせる(具体的で改善しやすい)。
2. 驚異の仕組み:3つのキー要素
Reflexionは主に3つの要素で構成されています。このシンプルなループが、強力な学習効果を生み出します。
- Actor(行動主体): タスクを実行するLLMエージェント。
- Evaluator(評価者): Actorの出力が正しいか評価する仕組み(テストケースなど)。
- Self-Reflection(自己反省): 失敗した理由を言語化し、改善策を生成するLLMモデル。
処理の流れ
- Actor がタスクに挑戦する(例:コードを書く)。
- Evaluator が失敗を判定する(例:エラーが出る)。
- Self-Reflection が失敗の原因を分析し、「次はこうしよう」という反省文(Reflective Text)を生成する。
- その反省文を メモリ(Episodic Memory Buffer) に保存する。
- Actor は次の挑戦時にメモリを読み、「反省」を活かして行動を修正する。
3. 実践的な成果:GPT-4を超える性能
この手法は理論だけでなく、ベンチマークでも圧倒的な結果を出しています。
1. コーディング性能 (HumanEval)
Pythonのコード生成タスクにおいて、GPT-4単体では 80% だった精度(Pass@1)が、Reflexionを適用することで 91% まで向上しました。これは当時のSOTA(最先端)記録を更新するものです。
2. 数学的推論と意思決定
AlfWorld(テキストベースのゲーム環境)やHotPotQA(推論が必要な質問応答)など、複数のステップが必要なタスクでも、単なるリトライ戦略などと比較して有意な改善が見られました。わずか数回のトライアル学習で、エージェントは「賢い立ち回り」を学習したのです。
3. なぜ「言葉」なのか?
数値の報酬よりも「言葉」のフィードバックの方が、LLMにとっては情報量が多く、解釈しやすいからです。「-1点」と言われるより、「鍵を持っていないからドアが開かない」と言われた方が、何をすべきか明確ですよね。
結論:エージェントAIは「自己進化」の時代へ
Reflexionが示したのは、AIモデル自体を再学習(Fine-tuning)させなくても、「プロンプト上のコンテキスト(短期記憶)」を最適化するだけで、AIは劇的に賢くなれる という事実です。
私たちは今、AIを単なる道具として使うだけでなく、AI自身に考えさせ、反省させ、成長させる「マネジメント」の手法を手に入れつつあります。
出典
- Original Paper: Reflexion: Language Agents with Verbal Reinforcement Learning (arXiv:2303.11366)
- Authors: Noah Shinn, Federico Cassano, et al.